昨日极限宗师yyh已经给大家介绍了如何安装并测试Microsoft NNI,今天就由他的学徒以Mnist-annotation这个demo为例给大家介绍一下如何使用NNI中的不同tuner进行超参数的搜索和调优。
关于NNI是什么在这里就不再次展开做详细的介绍了,大家可以参见上一篇文章。在这里为了便于大家理解,我将NNI做的事情用一句话粗略地概括一下:基于不同的搜索规则(Tuner)来选取超参数组合并训练模型,并根据模型在验证集上的表现确定最优的超参数。
本文重点介绍一下Tuner,Tuner本质上是各种调优算法在NNI框架中的实现,NNI提供了10种SOTA的调优算法,并在文档中对每种Tuner的适用场景和使用方法做了详细的说明,可以参考如下链接:Built-in Tuners
下面将以TPE和Random Search两种算法为例,演示如何使用NNI做超参数搜索:
要开始一个调优过程需要初始化一个experiment,相应的命令是
nnictl create --config nni/examples/trials/mnist-annotation/config_gpu.yml
可以看到创建一个experiment需要指明相应的配置文件,–config之后即为配置文件的路径,nni的仓库中为我们提供了一系列的示例配置,我们使用的mnist-annotation也是其中之一。值得注意的一点是,如果要使用GPU进行训练,需要使用样例配置中带有_gpu后缀的文件。那么,这些配置文件到底是什么样的呢,有没有_gpu又有什么区别呢,下面来一探究竟:
# nni/examples/trials/mnist-annotation/config_gpu.yml
authorName: default # 作者名
experimentName: example_mnist # 实验名称
trialConcurrency: 4 # 允许并发的trial数量
maxExecDuration: 1h # 最大运行时间
maxTrialNum: 10 # 最大trial数量
#choice: local, remote, pai
trainingServicePlatform: local # 运行的平台,local为本地
#choice: true, false
useAnnotation: true # 是否使用annotation
tuner:
#choice: TPE, Random, Anneal, Evolution, BatchTuner
#SMAC (SMAC should be installed through nnictl)
builtinTunerName: TPE # 使用的Tuner名,可以替换为上面的其他Tuner,如果使用SMAC的话需要额外安装插件
classArgs:
#choice: maximize, minimize
optimize_mode: maximize # 优化的方向,向极大值还是极小值
trial:
command: python3 mnist.py # 启动实验的命令的命令
codeDir: . # 代码路径
gpuNum: 1 # gpu数量
每一行的配置说明都在上面简要做了注解,有几个值得注意的地方是:
-
trialConcurrency决定了nni同时launch的trial数量,但是在单卡的情况下似乎还是只能一次进行一个trial的训练,其他已启动的trial会处于等待状态。至于能否在单卡上并行训练多个trial还有待探索,目前没有发现可配置的选项
-
maxExecDuration和maxTrialNum为什么时候停止搜索提供了两个条件,分别是到达最大的运行时间和运行到了指定数量的trial,除此之外,nni还可以通过配置Assessor来决定什么时候终止trial,这也在一定程度上决定了总的实验时间,关于Assessor的使用将在之后的文章中介绍。
-
useAnnotation确定了trial的代码中是否使用annotation语法来配置参数。annotation(或者叫注解)是现代代码框架中一个常用的扩展方式,它可以使开发者为程序包装上额外的功能而不必修改原本代码逻辑,只需要以类似注释的形式将annotation插入到指定的位置就大功告成了。在许多MVC框架中,annotation有着广泛的应用,典型的如Springboot,Django等等。NNI框架中的annotation支持如下的功能:
- 指明需要tune的变量
- 指明变量的调整范围
- 指明哪些变量会作为intermediate result即时的反馈到assessor中
- 指明那些变量会作为final result反馈到tuner
- 指明那些模型结构可以替换(function choise)
那么,与不使用annotation相比,这样的优点在哪里呢?对比mnist和mnist-annotation两个不同版本的文件夹内容,我们发现不使用annotation的版本需要额外附加一个search_space.json文件,并在config中说明serch_space文件的路径。其实这两种方案各有优劣,需要我们根据实际的使用需求加以权衡。annotation更加简单直接,但non-annotation将配置与源码分离,实际上更利于管理。
- tuner部分说明了使用的Tuner类型以及优化方式,更换Tuner只需要简单地更改这里的名字即可,我们一会将分别使用TPE和Random Search来做实验。
- gpuNum决定了是否使用以及使用多少GPU,比较直观
好了,分析过配置文件之后,我们来实际测试运行一下实验吧
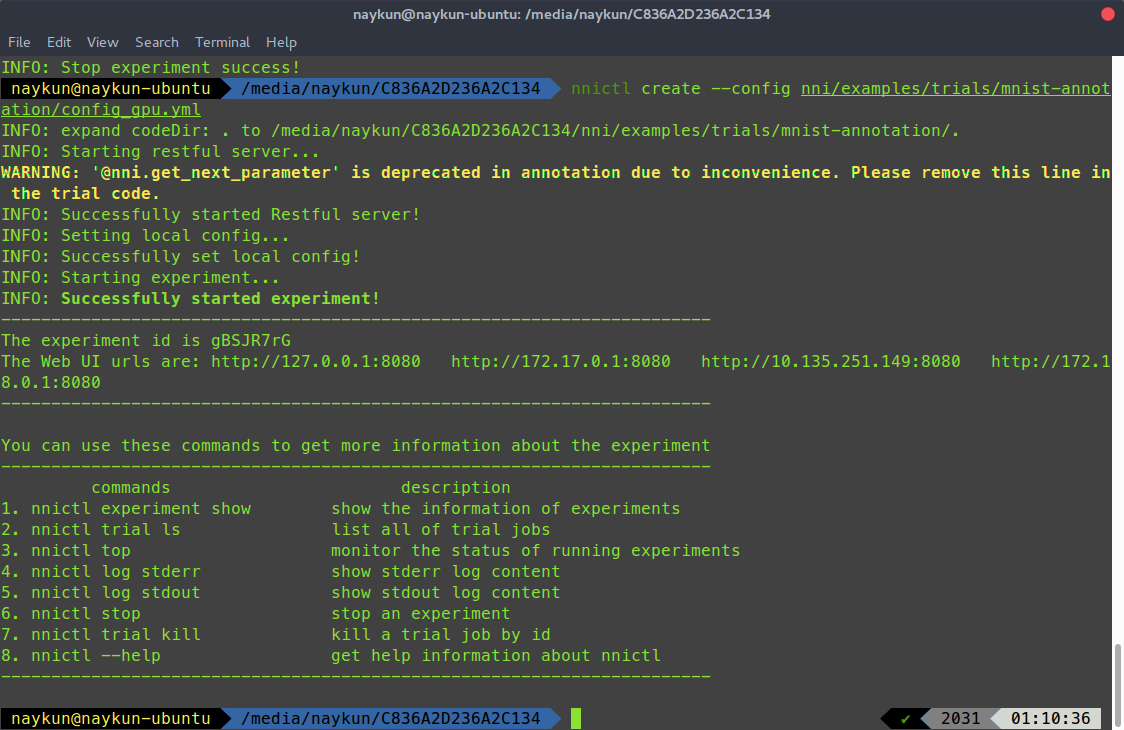
执行命令后,可以看到nni首先启动了一个web server来反馈实验的实时信息,并在之后加载配置文件,开始实验流程。实验启动成功后,会产生唯一的ID,我们稍后可以通过这个ID来控制这个experiment。点击WebUI的Url,就在浏览器打开了NNI的可视化界面:
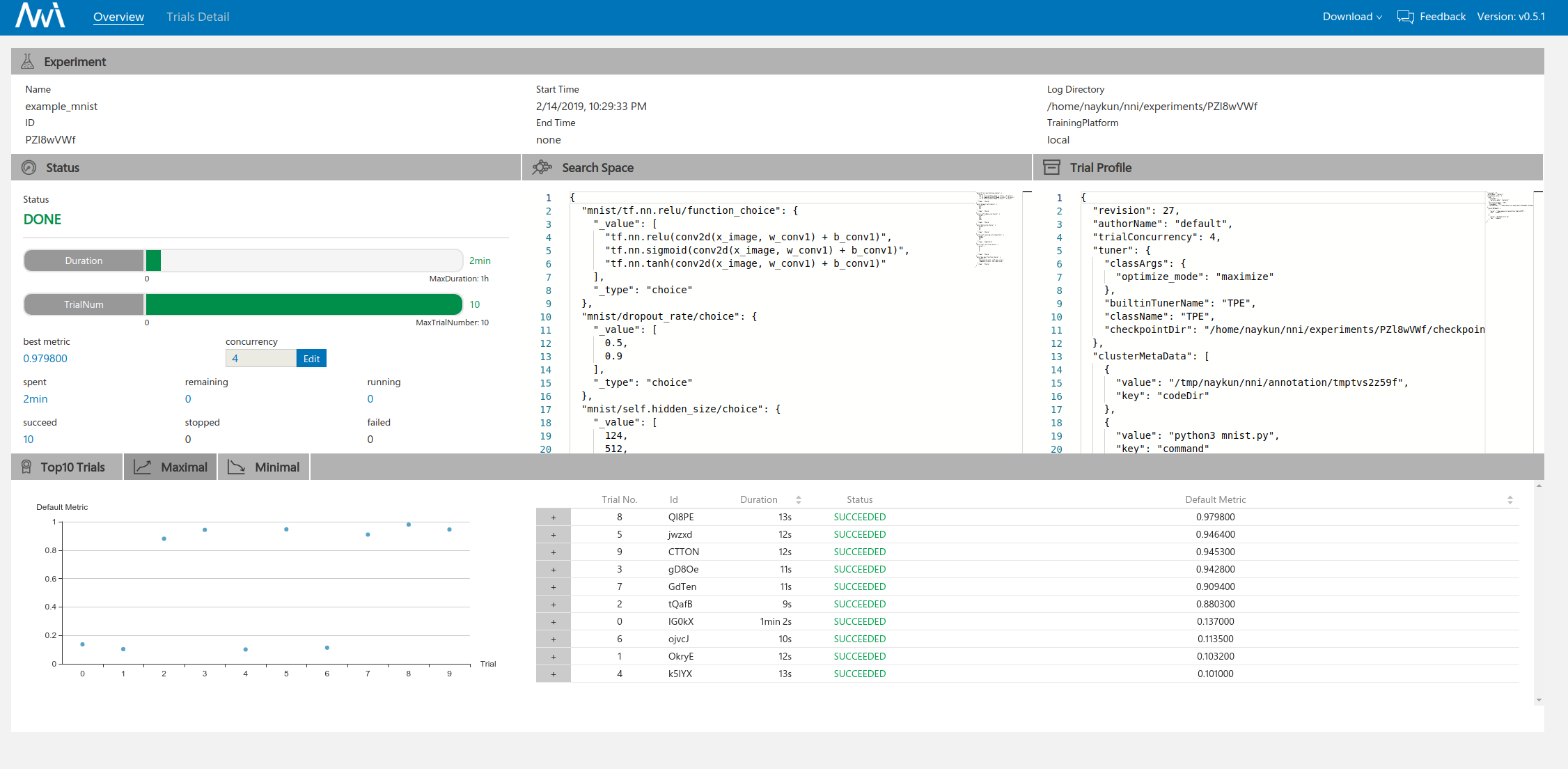
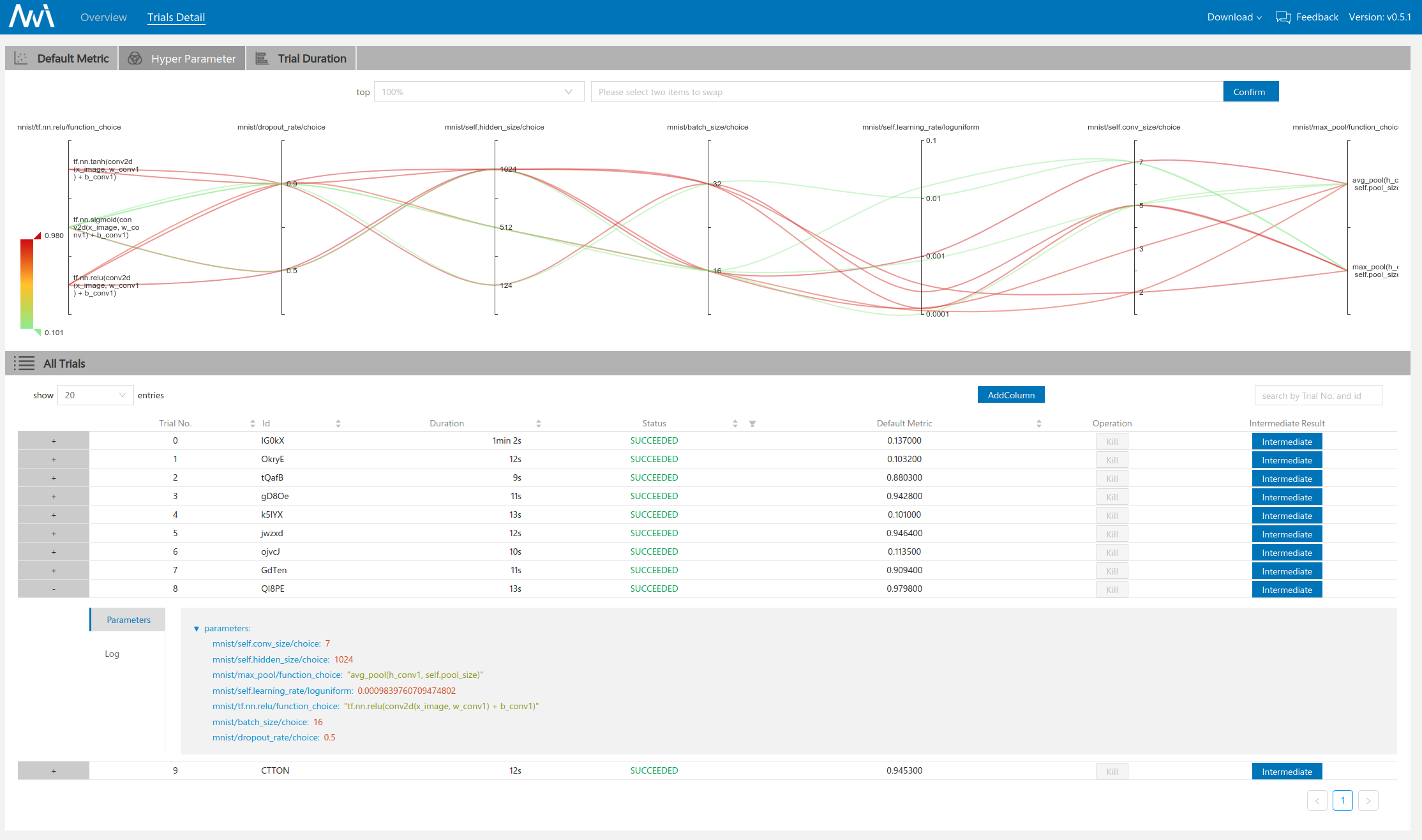
可以看到在界面1中间的部分指明了我们的超参数搜索空间以及experiment的配置信息。在界面二的上方以曲线的形式展示了不同trial的超参数设置情况。
第一次我们使用了TPE作为Tuner,可以看到在验证集上达到的最高准确率为0.979800。
接下来修改config文件,将tuner改为Random Search,classArgs不变,再次运行实验:
tuner:
builtinTunerName: Random
classArgs:
optimize_mode: maximize
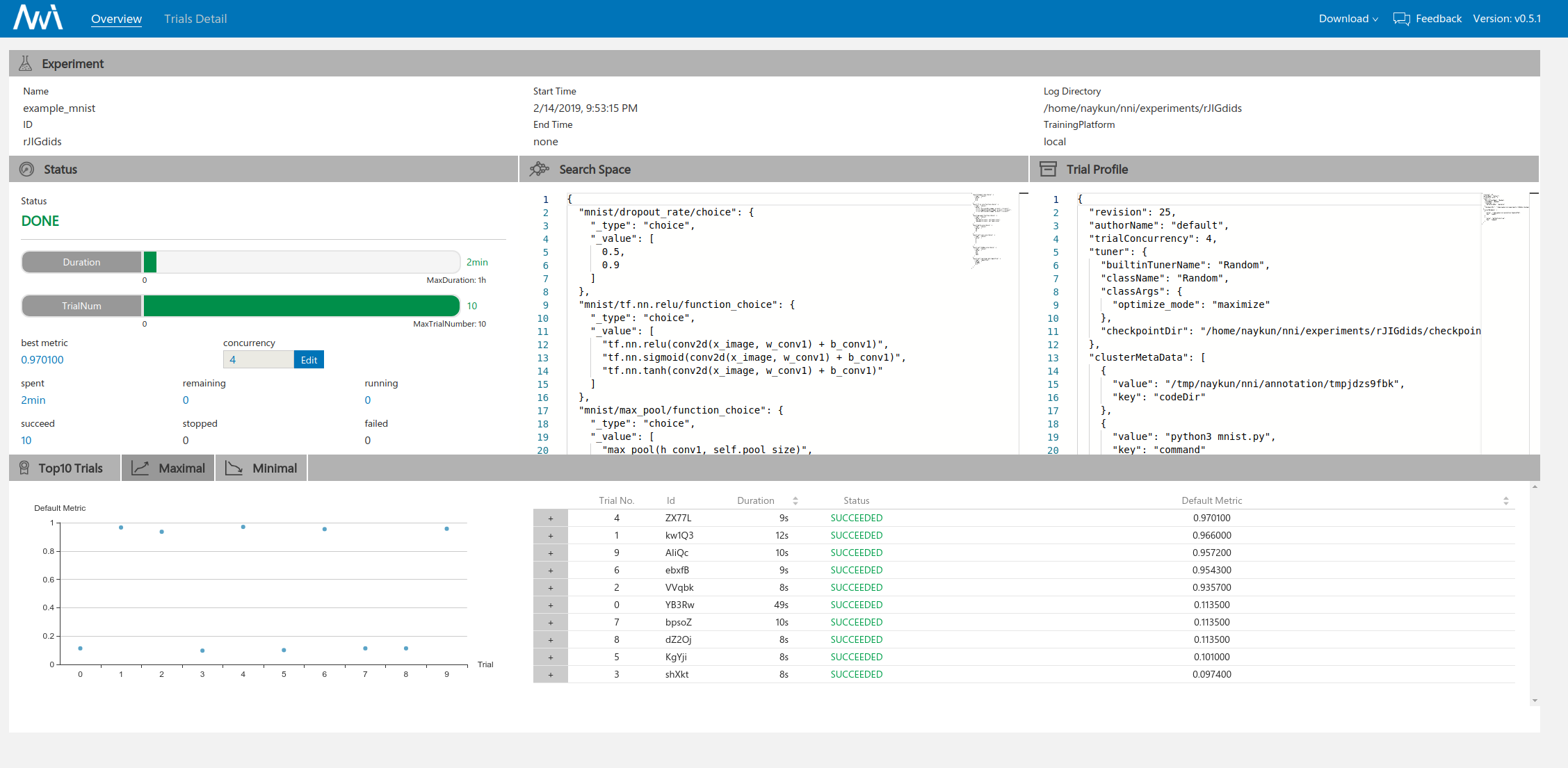
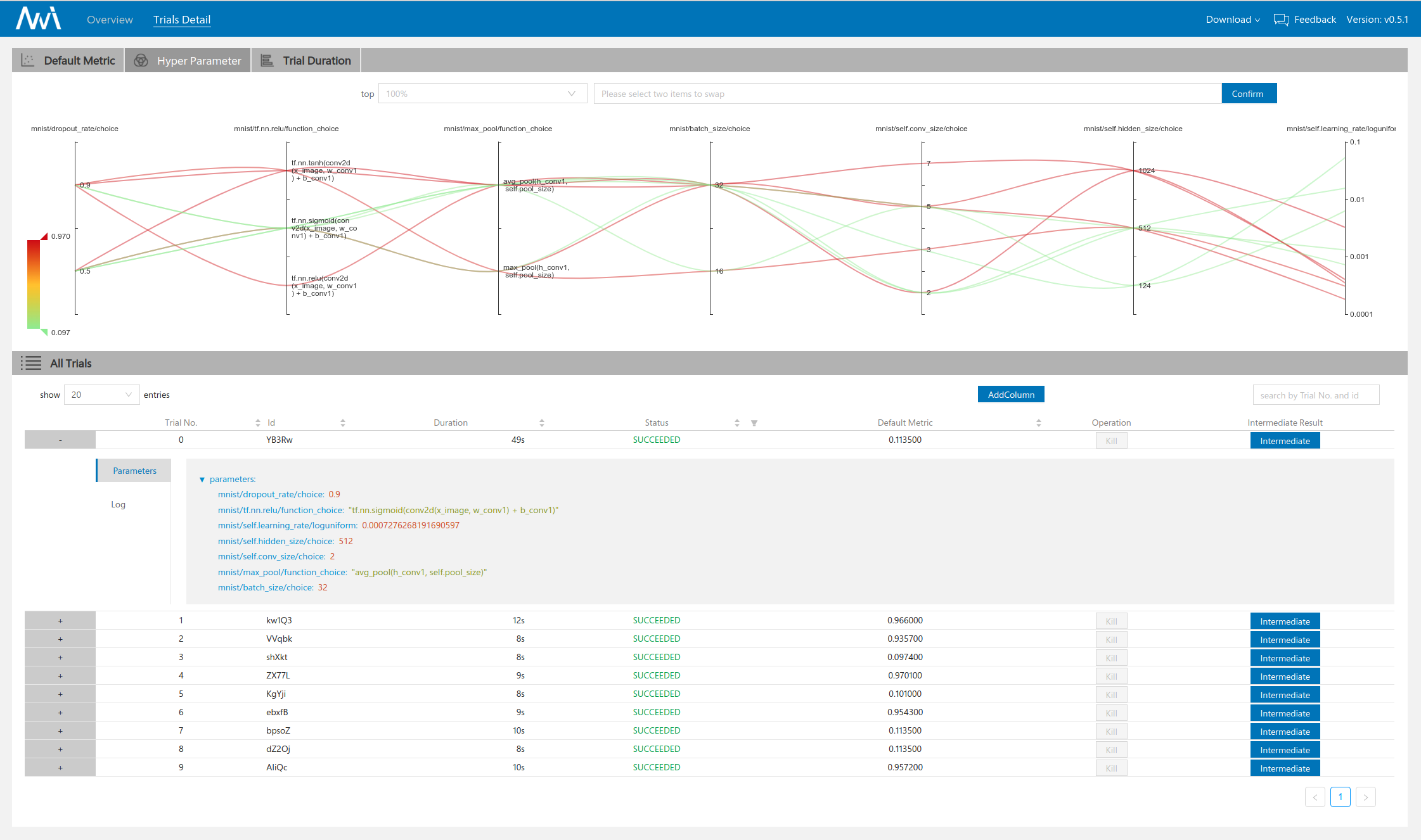
这次达到的最优准确率为0.970100。稍逊于TPE。
对比两种方法的超参数组合,我们可以发现似乎TPE的搜索组合发散性更强,在图中直观体现是曲线的重合度更低。不过,由于我们设置的trial数不多也没有在其他参数范围上做更general的测试,得到的这个结论可能并不具有代表性。根据文献中的建议,TPE更适用于计算资源有限,可尝试的trial数有限的场合,而random search往往需要更多的计算资源,常被用作搜索算法的baseline,对于大部分实验而言,TPE的性能要优于Random Search。
Anyway,到这里为止,已经向大家演示了如何在NNI中使用不同的tuner来搜索超参数,关于各个tuner更详细的介绍敬请期待之后的文章啦~
